Erfahrungen von Absolvent:innen
Hier finden Sie ein paar Beispiele, welche Themen in Projekt- und Abschlussarbeiten bearbeitet wurden. Folgen Sie den Links, wenn Sie mehr über die Themen und Erfahrungen Ihrer Kommiliton:innen wissen möchten.
Übersicht
Masterarbeiten
Modellierung von Struktur- und Verhaltensaspekten des Systemkontextes: Erweiterung der COSMOD-RE Methode
Insgesamt war es eine rundum gelungene Betreuung der Masterarbeit. Ich persönlich bin sehr zufrieden mit dem Ergebnis und würde den Lehrstuhl für eine Abschlussarbeit jederzeit empfehlen.
Katharina Isabel Böse, Masterarbeit 2021
Bachelorarbeiten
Variance analysis of an early life cycle defect prediction approach
Ich habe mich zu jedem Zeitpunkt gut unterstützt gefühlt und hatte bei Problemen stets eine Ansprechperson.
Maximilian Fiegen, Bachelorarbeit 2023

Automatische Erkennung von DSGVO-Datenschutzverletzungen in Laufzeitmodellen von Fog-Computing Systemen
Ich kann sagen, dass ich mit meiner Bachelor-Arbeit am SSE-Lehrstuhl sichtlich zufrieden bin, hinsichtlich des Themas, der Betreuung, des Ablaufes und natürlich auch des Ergebnisses.
Sascha Zmiewski, Bachelorarbeit 2022
Berücksichtigung von Reihenfolgeabhängigkeiten in Kontext-Featuremodellen und bei der Ableitung von Kripke-Strukturen
Die Hilfsbereitschaft sowie die Kommunikationsfähigkeit meines Betreuers war maßgeblich für den erfolgreichen Abschluss meiner Bachelorarbeit.
Yunus Altintas, Bachelorarbeit 2022
Erweiterung von UMLsec zur Modellierung von Datenschutzanforderungen und -gefährdungen im Fog-Computing
Wie bereits in dem Bachelorprojekt war die Betreuung auch in der Bachelorarbeit sehr gut und mein Betreuer war sehr daran interessiert, dass ich eine qualitativ hochwertige Arbeit verfasse.
Sven Smolka, Bachelorarbeit 2021
Nutzung realer Mobilitätsdaten in der Simulation von Location-Privacy-Angriffen im Fog-Computing
Entsprechend der Erfahrung aus dem (Bachelor-)Seminar – SSE war auch die Betreuung der Bachelorarbeit sehr gut.
Lukas Spiekermann, Bachelorarbeit 2021

Revealing the Marginal Effects of Predictor Variables in Black-box Software Defect Prediction Models Using Partial Dependence Plots and Individual Conditional Expectation
Insgesamt bin ich rundum zufrieden mit der Betreuung meiner Arbeit
Yunzhi Yan, Bachelorarbeit 2021

Experimental Assessment of Using Counterfactual Explanations for Exposing Biased Machine Learning Models
Ich bin mit der Betreuung meiner Bachelorarbeit durch meinen Supervisor vollends zufrieden.
Stefan Reining, Bachelorarbeit 2021

Erweiterung des Simulators MobFogSim zur Simulation von Location-Privacy-Angriffen auf Fog-Computing-Systeme
Besonders geholfen hat mir die sehr gute Betreuung, durch die die Arbeit viel Qualität gewinnen und sehr gut werden konnte.
Theresa Wettig, Bachelorarbeit 2020
Modellierung von Datenschutzgefährdungen im Fog-Computing anhand von Fallbeispielen aus dem EU-Forschungsprojekt FogProtect mithilfe der Modellierungssprachen UMLsec und SysML-Sec
Die Abschlussarbeit am Lehrstuhl SSE ermöglichte mir einen Einblick in das spannende Feld der künstlichen neuronalen Netze und dem Machine Learning.
Jan Laufer, Bachelorarbeit 2020

Untersuchung von Policy-based Reinforcement Learning bei dynamischen Änderungen des Zustandsraums am Beispiel eines adaptiven IoT-Systems
Durch das stets klare und ehrliche Feedback sowie die wöchentlichen Meetings habe ich bei der Bearbeitung zusätzliche Sicherheit gewonnen.
Tobias Braun, Bachelorarbeit 2020

Experimenteller Vergleich zwischen median- und mittelwert-basierten Ensembleprognosen für Geschäfts-prozesse
Ich würde am Lehrstuhl SSE immer wieder eine wissenschaftliche Arbeit schreiben wollen.
Norman Reddig, Bachelorarbeit 2019

Experimentelle Untersuchung der varianzbasierten Verlässlichkeitsschätzung BAGV für Prozessprognosen
Die Abschlussarbeit am Lehrstuhl SSE ermöglichte mir einen Einblick in das spannende Feld der künstlichen neuronalen Netze und dem Machine Learning.
Philipp Wallutis, Bachelorarbeit 2019

Evaluierung eines Algorithmus für die Ressourcenzuteilung in einer Cloud mit realen Nutzungsdaten
Wirklich gut fand ich den regelmäßigen Austausch über die aktuellen Ergebnisse und Ideen.
Michael Schröder, Bachelorarbeit 2017
Bachelorprojekte

Modellierung von Security-Aspekten von Fallbeispielen aus dem EU-Projekt FogProtect mithilfe ausgewählter Erweiterungen der BPMN
Feedback und konstruktive Kritik seitens des Betreuers erfolgten rechtzeitig und in einer angenehmen, offenen und hilfreichen Art.
Nicolas Hasselhuhn, Bachelorprojekt 2021

Erweiterung eines dezentralen Algorithmus für die Platzierung von Anwendungskomponenten im Fog-Computing
Die Kommunikation mit dem Betreuer verlief auf Augenhöhe und trug positiv zum Arbeitsklima bei der Erstellung der Arbeit bei.
Leon Wißenberg und Sven Smolka, Bachelorprojekt 2021
Erfahrungsberichte
Maximilian Figen: Variance analysis of an early life cycle defect prediction approach, Bachelorarbeit, 2023
Abstract
Faults in the source code may lead to failures. Failures of software systems do not only cause problems for the users, but also for the stakeholders and the developers. Identifying and fixing faults is an expensive and time-consuming task. Recently; researchers and developers are adopting Machine learning (ML) to automate the process of identifying fault-prone areas in source code. For that purpose, they are using historical faulty data to train fault predictors. Fault predictors are used to predict fault-prone areas of a code base.
In this thesis, we are analyzing the variance of a practical approach to fault prediction using early life cycle software defect prediction software. The focus will be put on the non-deterministic factors that occur in machine learning and how they impact the accuracy results of the fault prediction models. To measure this effect, we performed 16 identical training runs on the early life cycle software under different NI-factor configurations for Random Forest, Naive Bayes, and Logistic Regression. We trained and measured the accuracy of the model with algorithmic NI-factors turned on, algorithmic NI-factors turned off, and only one NI-factors being active at a time. In addition, we also recorded the run time for each training run we performed. We evaluated the results using Brier, IFA, Recall, PF, AUC, D2H, and the G-measure. Additionally, we performed The Levene test as well as the Mann-Whitney U-test to measure the statistical significance. We found that SMOTE as an isolated NI-factor greatly contributes to reducing accuracy variance but also almost doubles the run time in some cases. The SMOTE results were found to be statistically significant after passing the Levene and Mann-Whitney U tests.
Persönliches Fazit
"Die Betreuung während meiner Bachelorarbeit war sehr gut. Ich habe mich zu jedem Zeitpunkt gut unterstützt gefühlt und hatte bei Problemen stets eine Ansprechperson."
Sascha Zmiewski: Automatische Erkennung von DSGVO-Datenschutzverletzungen in Laufzeitmodellen von Fog-Computing Systemen, Bachelorarbeit, 2022
Abstract

Das Fog-Computing ermöglicht die Nutzung von Speicher- und Rechenresourcen in geographischer Nähe von Endgeräten, um somit die Defizite des Cloud-Computings auszugleichen. Der Schutz von personenbezogenen Daten in einem Fog-Computing System wird durch die Eigenschaften und die Architektur eines Fog-Computing Systems erschwert. Ein Ansatz für die Wahrung des Datenschutzes ist Run-time ADaptations for DAta pRotection. In diesem Ansatz werden mögliche Datenschutzrisiken und -verletzungen als Problematic Configuration Patterns modelliert. Ein Fog-Computing System wird als Laufzeitmodell modelliert und anhand eines Pattern Matching Algorithmus auf die Existenz der Problematic Configuration Patterns untersucht.
Die Problematic Configuration Patterns können beliebige Datenschutzrisiken darstellen. Jedoch werden diese spezifisch für ein modelliertes System erstellt. Die Datenschutz-Grundverordnung der Europäischen Union definiert Richtlinien für den Datenschutz, welche in jedem System eingehalten werden müssen. Torre et al. stellen ein konzeptuelles Modell vor, welches die Konzepte der Datenschutz-Grundverordnung abbildet. Ein Bestandteil des konzeptuellen Modells von Torre et al. sind 35 “Einschränkungsregeln”, welche allgemeingültige Datenschutzverletzungen abbilden.
Ziel dieser Arbeit ist die Überführung eines Teiles der allgemeingültigen Datenschutzverletzungen in Problematic Configuration Patterns. Dafür wird das konzeptuelle Modell von Torre et al. analysiert und Anforderungen für die Abbildung der allgemeingültigen Datenschutzverletzungen erhoben. Das Metamodell von Run-time ADaptations for DAta pRotection wird auf die Erfüllung der Anforderung untersucht und stellenweise erweitert. Eine Auswahl der allgemeingültigen Datenschutzverletzungen von Torre et al. wird als Problematic Configuration Patterns modelliert und somit das Ziel der Arbeit erfüllt. Die modellierten Problematic Configuration Patterns werden anhand eines Anwendungsbeispiels erprobt und diskutiert.
Persönliches Fazit
„Durch die Proposal-Phase konnte direkt festgestellt werden, ob das notwendige Verständnis für die weitere Bearbeitung eines Themas gegeben ist. In diesem Zusammenhang ist der Proposal-Vortrag und das Feedback der wissenschaftlichen Mitarbeiter des Lehrstuhls positiv zu erwähnen. Durch diese beiden Dinge konnten mögliche Störfaktoren für die Bachelor-Arbeit identifiziert werden und das geplante Vorgehen verbessert werden.
Das regelmäßig stattfindende Kolloquium war ebenfalls von positiver Bedeutung. Die Präsentationen anderer Kommilitonen waren eine gute Inspiration für die eigene Präsentation. Dies gilt sowohl für den Proposal-Vortrag als auch für den Abschlussvortrag.
Während der Bearbeitung meiner Bachelor-Arbeit war das kontinuierliche Feedback meines Betreuers ein besonders positiver Aspekt. Meine eigene Bearbeitung erfolgte somit nicht „auf dem letzten Drücker“, sondern in inkrementellen Schritten, wodurch das Gesamtergebnis meiner Arbeit verbessert wurde. […]
Ich kann sagen, dass ich mit meiner Bachelor-Arbeit am SSE-Lehrstuhl sichtlich zufrieden bin, hinsichtlich des Themas, der Betreuung, des Ablaufes und natürlich auch des Ergebnisses. Dementsprechend kann ich eine Bachelor-Arbeit am SSE-Lehrstuhl nur empfehlen.“
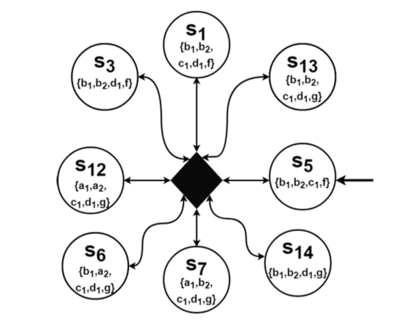
Yunus Altintas: Berücksichtigung von Reihenfolgeabhängigkeiten in Kontext-Featuremodellen und bei der Ableitung von Kripke-Strukturen, Bachelorarbeit, 2022
Abstract

Auf Grundlage eines Ansatzes zur Analyse des funktionalen Zusammenspiels kollaborierender Systeme mittels Feature-Modellen und daraus erzeugten Kripke-Strukturen des Verhaltens konkreter Kollaborationen wurde ein Ansatz entwickelt, der zusätzlich Reihenfolgeabhängigkeiten berücksichtigt. Diese Reihenfolgeabhängigkeiten sollen neben den bereits existieren Abhängigkeiten neue Einschränkungen für das Systemverhalten einer konkreten Kollaboration bereitstellen. Durch Reihenfolgeabhängigkeiten sollen Reihenfolgen bezüglich der Aktivierung von Features festgelegt werden. Die Syntax und Semantik von Reihenfolgeabhängigkeiten werden in diesem Ansatz formal definiert, so dass Modellierungen auf Typebene ermöglicht werden und durch die Instanziierung dieser Abhängigkeit weitere Einschränkungen für das Systemverhalten berücksichtigt werden. Durch die festgelegte Semantik müssen Anpassungen an den Kripke-Strukturen vorgenommen werden. Hierfür wurden die verschiedenen Algorithmen entwickelt. Um die Anwendbarkeit des Ansatzes zu untersuchen, wird zum Schluss der Ansatz am Fallbeispiel „Vehicle Platoning“ erprobt.
Persönliches Fazit
"Wie zuvor in der Seminararbeit war auch die Betreuung in der Bachelorarbeit besonders positiv. Durch wöchentliche Absprachen mit meinem Betreuer konnte ich Problemstellungen während der Bearbeitung der Bachelorarbeit gut bewältigen, so dass das Endergebnis für mich sehr zufriedenstellend war. Die Hilfsbereitschaft sowie die Kommunikationsfähigkeit meines Betreuers war maßgeblich für den erfolgreichen Abschluss meiner Bachelorarbeit.
Außerdem empfand ich den strukturellen Ablauf zur Bearbeitung der Bachelorarbeit äußerst positiv. Durch die Erstellung eines Proposaldokuments und den darauffolgenden Proposalvortrag konnten durch das gute Feedback vom Lehrstuhl offene Fragen noch geklärt und angegangen werden."
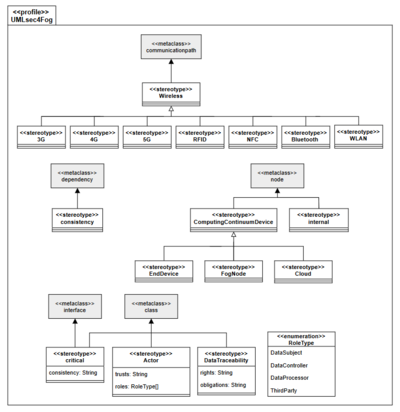
Sven Smolka: Erweiterung von UMLsec zur Modellierung von Datenschutzanforderungen und -gefährdungen im Fog-Computing, Bachelorarbeit, 2021
Abstract

Fog-Computing ist ein aufstrebender Ansatz, in welchem der zentralisierte Ansatz des Cloud-Compu-ting erweitert wird, indem Rechen- und Speicherressourcen näher an Endgeräte verlagert werden. Die Endgeräte können anschließend zu verarbeitende Daten an Fog-Knoten auslagern. Die Datenverarbeitung erfolgt anschließend auf den Fog-Knoten, wodurch es zeitkritischen Anwendungen möglich ist, ihre Echtzeitanforderungen zu erfüllen.
Eine Herausforderung des Fog-Computing ist der Schutz personenbezogener Daten, welcher auf-grund von Gesetzen wie der Datenschutz-Grundverordnung (DSGVO) gewährleistet sein muss. Diese Herausforderung ist durch die hohe Dynamik der Fog-Systeme und die Charakteristika der Fog-Knoten begründet. Um diese Herausforderung zu überwinden, bedarf es unter anderem Datenschutzanforderun-gen und Datenschutzgefährdungen bei der Modellierung von Fog-Systemen zu berücksichtigen. In einer vorangegangenen Arbeit haben Laufer et al. untersucht, inwiefern sich Datenschutzanforderungen und Datenschutzgefährdungen im Fog-Computing mit dem UML-Profil UMLsec modellieren lassen. Hin-sichtlich der Modellierung von Datenschutzanforderungen und Datenschutzgefährdungen mit UMLsec identifizierten die Autoren sieben Modellierungseinschränkungen in UMLsec Verteilungs- und Klassen-diagrammen.
Ziel dieser Arbeit ist die Entwicklung des UML-Profils UMLsec4Fog, welches eine Erweiterung des UMLsec-Profils ist und in welchem die sieben von Laufer et al. identifizierten Modellierungseinschrän-kungen überwunden werden. Des Weiteren wird das UML-Profil UMLsec4Fog technisch in dem Mo-dellierungswerkzeug Papyrus umgesetzt. Letztlich findet eine Erprobung des UML-Profils UMLsec4Fog statt, indem die UMLsec Verteilungs- und Klassendiagramme der drei Fallbeispiele Smart Manufactu-ring, Smart Media und Smart City des europäischen Forschungsprojektes FogProtect mithilfe des UML-Profils UMLsec4Fog überarbeitet werden.
Aus der Erprobung des UMLsec4Fog-Profils geht hervor, dass sich die sieben Modellierungsein-schränkungen, welche in den UMLsec Verteilungs- und Klassendiagrammen der drei Fallbeispiele des europäischen Forschungsprojektes existieren, überwinden lassen.
Persönliches Fazit
"Wie bereits in dem Bachelorprojekt war die Betreuung auch in der Bachelorarbeit sehr gut und mein Betreuer war sehr daran interessiert, dass ich eine qualitativ hochwertige Arbeit verfasse. Dies spiegelte sich vor allem darin wider, dass ich wöchentlich ausführliches Feedback über den aktuellen Stand meiner Ausarbeitung erhalten habe.
Die wöchentlichen Meetings und einhergehenden Diskussionen mit meinem Betreuer, welche alle auf Augenhöhe erfolgten, haben mir zudem sehr bei dem Verfassen meiner Arbeit geholfen. Als ich auf Probleme gestoßen bin, war mein Betreuer immer erreichbar, sodass ich schnell Hilfe bekam und nicht lange auf eine Rückmeldung warten musste. Auch die Möglichkeit, sein Thema und methodisches Vorgehen in einer Zwischenpräsentation anderen wissenschaftlichen Mitarbeitern vorzustellen, empfinde ich als eine sehr gute Möglichkeit in der frühen Phase der Bachelorarbeit neue Gedankengänge, Ideen sowie konstruktive Kritik zu erhalten."
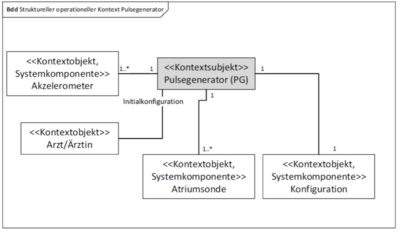
Katharina Isabel Böse: "Modellierung von Struktur- und Verhaltensaspekten des Systemkontextes: Erweiterung der COSMOD-RE Methode", Masterarbeit, 2021
Abstract

Eingebettete software-intensive Systeme sind in übergeordnete Produkte integriert und interagieren über Sensoren und Aktoren eng mit der physischen Umgebung. Daher ist die systematische Berücksichtigung des operationellen Kontextes in der Entwicklung derartiger Systeme wesentlich. Die COSMOD-RE Methode unterstützt die verzahnte Entwicklung modellbasierter Anforderungs- und Architekturartefakte für eingebettete Systeme. COSMOD-RE unterscheidet mit Hilfe von Abstraktionsebenen zwischen der Essenz und der Inkarnation des Systems, und unterstützt zudem die Verfeinerung von Artefakten auf Granularitätsebenen innerhalb der Abstraktionsebenen. Die COSMOD-RE Methode sieht allerdings keine dedizierten Kontextmodelle vor. Es fehlt hierbei eine konzeptuelle Grundlage für die explizite Berücksichtigung von Kontextinformationen auf den Abstraktionsebenen. Kontextinformationen werden lediglich implizit, beispielsweise als Teil eines Anforderungsmodells, spezifiziert. Das Ziel dieser Arbeit ist es, die konzeptuelle Grundlage für Modelle des operationellen Kontextes in COSMOD-RE zu etablieren. Das Kernprinzip der Unterscheidung zwischen Essenz und Inkarnation wird auf die Kontextbetrachtung übertragen. Die Unterscheidung zwischen Essenz und Inkarnation des Kontextes ordnet sich dabei orthogonal in die COSMOD-RE-Abstraktionsebenen ein- Essenzielle und technologieabhängige Kontextmodelle sind sowohl für die Spezifikation der Essenz des zu entwickelnden Systems als auch dessen technologiespezifischer Realisierung mittels Hard- und Software. Zudem wird die Verfeinerung von Kontextmodellen anhand der Systemdekomposition auf tieferen Granularitätsebenen untersucht. Die entwickelten Konzepte stellen die Grundlage für die Definition konkreter Modellierungssprachen dar. Der Fokus liegt hierbei auf Struktur- und Verhaltensmodellen des operationellen Kontextes. Die in dieser Arbeit entwickelte konzeptuelle Erweiterung von COSMOD-RE wird anhand der Fallbeispiele eines Herzschrittmachers und eines Adaptive Cruise Control illustriert. Des Weiteren wird der erwartete Nutzen und mögliche Validitätseinschränkungen diskutiert.
Persönliches Fazit
"Besonders positiv fand ich den Proposalvortrag, um das Thema nochmal zu diskutieren und zu fokussieren sowie Anregungen von anderen außenstehenden Personen zu erhalten. Ebenfalls gut hat mir der stetige Austausch mit meinem Betreuer gefallen, der alles dafür getan hat, dass die Masterarbeit bestmöglich gelingt.
Insgesamt war es eine rundum gelungene Betreuung der Masterarbeit. Ich persönlich bin sehr zufrieden mit dem Ergebnis und würde den Lehrstuhl für eine Abschlussarbeit jederzeit empfehlen."
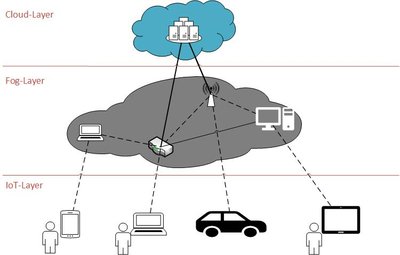
Lukas Spiekermann: "Nutzung realer Mobilitätsdaten in der Simulation von Location-Privacy-Angriffen im Fog-Computing", Bachelorarbeit, 2021
Abstract

In Fog systems, computing resources are offered between end devices and cloud servers in the form of Fog nodes. These Fog Nodes are characterised above all by their heterogeneity and geographical distribution. They offer a variety of possible services, such as storage close to end devices, and thus enable real-time applications that require low latency. However, the heterogeneity of Fog nodes could also give rise to risks. For example, Fog nodes whose computing power is not sufficient to ensure adequate security of the sensitive data they process could pose a threat. Since Fog nodes often process the data of nearby users, location-privacy risks may arise in Fog systems for these users. For instance, attackers controlling a Fog node could approximate the locations of users which are currently communicating with that Fog node. Attackers who control multiple Fog nodes could even trace the trajectories of users.
The simulator LocPrivFogSim was developed in a previous work to simulate different scenarios that involve such location-privacy risks. The simulation results from that previous work show that even a small number of compromised Fog nodes can be sufficient to accurately determine both the location and trajectory of a user. However, one shortcoming of the test system used for these simulations is that randomly generated paths are used for the simulations instead of real user paths. But these randomly generated paths could have influenced the simulation in such a way that the location privacy risk was misjudged. Thus, a repetition of the simulation with real mobility data seems appropiate in order to be able to discuss this effect.
The aim of this work is therefore to extend LocPrivFogSim in such a way that real mobility data can be used for simulation. For this purpose, the GeoLife dataset collected by Microsoft Research Asia is integrated into LocPrivFogSim. The simulation results conducted with this extension will then be evaluated and compared to the findings of T. Wettig and Z.Á. Mann.
Persönliches Fazit
"Entsprechend der Erfahrung aus dem (Bachelor-)Seminar – SSE war auch die Betreuung der Bachelorarbeit sehr gut. So wurden in wöchentlichen Meetings sowohl aktuelle Ergebnisse als auch die nächsten Schritte ausführlich besprochen, wodurch das zielgerichtete/wissenschaftliche Arbeiten deutlich erleichtert wurde. Neben der Betreuung war insbesondere das Feedback im Anschluss des Proposal-Vortrags sehr hilfreich, die Ziele der Arbeit weiter zu präzisieren."
Nicolas Hasselhuhn: "Modellierung von Security-Aspekten von Fallbeispielen aus dem EU-Projekt FogProtect mithilfe ausgewählter Erweiterungen der BPMN", Bachelorprojekt, 2021
Abstract

Mit der stark steigenden Anzahl vernetzter Systeme erhöht sich die Menge der erzeugten und zu verarbeitenden Daten enorm, sodass im Zusammenhang mit den begrenzten Ressourcen von IoT-Devices, alternative Topologie orientierte Berechnungsparadigmen, wie Mist-Computing, Fog-Computing oder Edge-Computing definiert worden sind. Die Auslagerung von Berechnungen auf die Fog-Devices führt gerade durch die hohe Dynamisierung des Fog-Netzwerks dazu, dass neue Anforderungen und Herausforderungen an die IT-Sicherheit entstehen. Den Herausforderungen soll im Rahmen des FogProtect Projektes, unter Beachtung von Industriestandards wie ISO/IEC 27000:2018 begegnet werden, in dem Betrachtungen von Datenschutzrisiken anhand von Use-Cases durchgeführt werden. In Unternehmen sind Modellierungen von Geschäftsprozessen in BPMN weitverbreitet, jedoch ist in BPMN die Modellierbarkeit von IT-Security bezogenen Prozessen nicht standardisiert. In dieser Arbeit werden drei Vorschläge zur Erweiterung von BPMN um Elemente zur Modellierung von IT-Sicherheits-Aspekten, unter Zuhilfenahme der FogProtect Use-Cases Smart City und Smart Manufacturing, hinsichtlich der Modellierbarkeit von Security-Aspekten evaluiert und verglichen. Initial wurden in dieser Arbeit die Use-Cases in BPMN modelliert um diese im weiteren Verlauf um die im FogProtect deliverable 2.1 beschriebenen Datenschutzrisiken mithilfe der BPMN-Erweiterungen zu modellieren. Diese Arbeit zeigt, dass eine Modellierung von Security-Aspekten, auf Basis der Datenschutzrisiken, durch die Erweiterungen ermöglicht wird und in dem Zusammenhang die Unterschiede, sowie die Vor- und Nachteile der einzelnen Erweiterungen aufgezeigt werden können.
Persönliches Fazit
"Der Ablauf der Arbeit war sehr gut strukturiert. Man erstellt sich selbst einen Zeitplan und überprüft den Fortschritt in den wöchentlichen Abstimmungen. Durch regelmäßiges Feedback zum Fortschritt im Projekt konnte der Fokus auf die Aufgabenstellung immer gewahrt werden, wodurch unnötige Mehrarbeit vermieden wurde. Die Betreuung und Kommunikation während der Arbeit fand sehr ausführlich, angenehm und auf Augenhöhe statt. Es gab eine sehr gute Unterstützung bei der wissenschaftlichen Herangehensweise in der Arbeit. Feedback und konstruktive Kritik seitens des Betreuers erfolgten rechtzeitig und in einer angenehmen, offenen und hilfreichen Art. Leider überschreitet der Umfang der Arbeit den gerechtfertigten Zeitaufwand für 9 CP."
Yunzhi Yan: "Revealing the Marginal Effects of Predictor Variables in Black-box Software Defect Prediction Models Using Partial Dependence Plots and Individual Conditional Expectation", Bachelorarbeit, 2021
Abstract
Software defect prediction has become more and more important during software development. Identifying the error-prone software modules qualitatively and efficiently is a challenging task for both academic and industrial organizations. Even if a functional prediction model is available, its inner logic and causal relations may not easily understandable by humans. In this thesis, this problem is tackled by utilizing two explainable artificial intelligence (XAI) techniques, namely Partial Dependence Plot (PDP) and Individual Conditional Expectation (ICE), to comprehensively explain the software defect prediction model. Together with XAI, a multilayer perceptron is used to reveal the most important features that could lead to a software defect.
According to the experiment on NASA Metrics Data Program (MDP) Software Defects Data Sets, the feature LOC_CODE_AND_COMMENT, LOC_BLANK, and GLOBAL_DATA_COMPLEXITY have the largest influence on the defect prediction. While the feature HALSTEAD_CONTENT has the least influence on the defect prediction. In general, the PDP results show the average effect of one or two features on the defect prediction, while the ICE results, on the other hand, discover some heterogeneous relationships that might be hidden in PDP. Furthermore, it has been discovered that atypical behavior in the PDP and ICE plots are mostly cost by imbalanced feature distribution. In addition to 1-dimensional PDP and ICE plots, in this thesis, 2-dimensional and 3-dimensional PDP plots are utilized to visualize the interaction between two features, which reveal their deeper relations with software defect probability. Overall, my result indicates that the combination of PDP and ICE are sufficient techniques to explain an artificial intelligence classification model even without considerable expertise in a domain.
Persönliches Fazit
"Mein Betreuer während meiner Arbeit war sehr nett und hilfreich. Er teilte mir immer klar den Ablauf, die Anforderungen und den Schwerpunkt meiner Arbeit mit. Ebenfalls sagte er mir, was unerheblich ist und weggelassen werden konnte. Er gab mir mehrfach nützliches Feedback und war sehr verantwortungsbewusst. Wenn ich Fragen hatte, antwortete er mir immer schnell und verständlich. Insgesamt bin rundum zufrieden mit der Betreuung meiner Arbeit."

Sven Smolka und Leon Wißenberg: "Erweiterung eines dezentralen Algorithmus für die Platzierung von Anwendungskomponenten im Fog-Computing“, Bachelorprojekt, 2021
Abstract

Fog-Computing ist ein aufstrebendes Paradigma, welches den zentralisierten Ansatz des Cloud-Computing erweitert, indem Rechen- und Speicherressourcen näher an die Endgeräte verlagert wer-den. Endgeräte können infolgedessen Bearbeitungsaufgaben an die Fog-Knoten versenden. Im Fog-Computing werden Komponenten von Anwendungen auf den Fog-Knoten (oder den Cloud-Servern) platziert. Die Komponenten auf den Fog-Knoten können die Bearbeitungsaufgaben der Endgeräte in Echtzeit verarbeiten. Die Entscheidung, wo jede Komponente einer Anwendung platziert werden soll, erfolgt dabei durch Algorithmen, welche zentral oder dezentral ausgeführt werden. In der Vergangenheit haben die Autoren Malek et al. einen dezentralen Algorithmus, genannt DecAp Algorithmus, entwickelt, welcher die Verfügbarkeit eines verteilten Systems verbessert.
Im Rahmen dieser Arbeit wurde der dezentrale DecAp Algorithmus von Malek et al. modifiziert, sodass dieser für die Entscheidungsfindung der Platzierung von Komponenten im Fog-Computing eingesetzt werden kann. Dabei zielt der modifizierte DecAp Algorithmus darauf ab, die Ausführungszeit der Anwendung zu verbessern. Außerdem wurde eine eigene Simulationsumgebung entwickelt, in welcher der modifizierte DecAp Algorithmus auf seine Funktionalität überprüft wurde. Ferner wurde der modifizierte DecAp Algorithmus qualitativ und quantitativ in drei Experimenten evaluiert. Dabei wurde der Algorithmus mit einem bereits existierenden dezentralen Algorithmus von Guerrero et al. und einem zentralen Cloud-Only Algorithmus verglichen. Aus den Ergebnissen der Evaluation geht hervor, dass der DecAp Algorithmus für alle evaluierten Probleminstanzen das beste Optimierungspotential für die Ausführungszeit hat. Bei großen Probleminstanzen erreichte der Algorithmus eine Verbesserung von etwa 80% bis 90%.
Persönliches Fazit
Sven Smolka
„Ich fand die Betreuung in dem Bachelorprojekt sehr gut. Die Möglichkeit, mich wöchentlich mit meinem Betreuer zu treffen und über die Inhalte und den Fortschritt zu reden, hat mir sehr geholfen. Auch, dass sich mein Betreuer die Ausarbeitung regelmäßig angeschaut und dazu Feedback gegeben hat, war enorm hilfreich. Ebenso fand ich bemerkenswert, dass mein Betreuer sehr schnell auf Emails geantwortet hat.
Die Zwischenpräsentation ist sehr nützlich, da man hier konstruktive Kritik von den anderen wissenschaftlichen Mitarbeitern des Lehrstuhls erhalten kann."
Leon Wißenberg
„Ich fand es sehr gut, dass es ein wöchentliches Meeting zum aktuellen Stand gab, in dem sowohl Fragen geklärt werden konnten als auch der Betreuer Feedback gegeben hat. Bei Problemen konnte zudem der Kontakt via Mail genutzt werden, um jederzeit Probleme oder Fragen abzuklären. Die Kommunikation mit dem Betreuer verlief auf Augenhöhe und trug positiv zum Arbeitsklima bei der Erstellung der Arbeit bei.“
Stefan Reining „Experimental Assessment of Using Counterfactual Explanations for Exposing Biased Machine Learning Models“, Bachelorarbeit, 2021
Abstract

Die Verwendung von Machine-Learning-Algorithmen mag aufgrund einer scheinbaren Erhöhung von Objektivität als ein vielversprechendes Mittel gegen menschliche Voreingenommenheit erscheinen. Jedoch hat sich die auf Machine-Learning-Algorithmen basierende Entscheidungsfindung selbst vielerorts als anfällig für so genannten Bias herausgestellt. Darüber hinaus wird die allgemeine Bereitschaft, sich auf diese Art der Entscheidungsfindung zu verlassen, durch die Tatsache beeinträchtigt, dass es aufgrund der inneren Komplexität einiger Arten von Machine-Learning-Modellen oft praktisch unmöglich ist, derartige Entscheidungen in einer Art und Weise zu erklären, die für diejenigen Personen verständlich ist, welche von diesen Entscheidungen betroffen sind. Im Zuge dieser Entwicklungen ist in den vergangenen Jahren ein Forschungsfeld namens Explainable Artificial In-telligence (XAI) entstanden, welches das Ziel verfolgt, die Entscheidungen so genannter Black-Box-Modelle interpretierbar zu machen. Die vorliegende Arbeit beschäftigt sich mit einer bestimmten XAI-Technik: der Technik der kontrafaktischen Erklärung. Nachdem zunächst einige theoretische Fundierungen bezüglich des Begriffs des algorithmischen Bias und der Funktionsweise der Technik der kontrafaktischen Erklärung vorgenommen werden, wird eine im Rahmen des ALIBI-Frameworks bereitgestellte Implementierung dieser Technik auf Modelle angewendet, die auf zwei bekanntermaßen von Bias betroffenen Datensätzen trainiert werden: der StatLog German Credit Datensatz, bestehend aus Ratings bezüglich Kreditwürdigkeit, sowie der ProPublica COMPAS Datensatz, bestehend aus Einschätzungen der Rückfallwahrscheinlichkeit von Straftätern. Die Implikationen der Resultate dieser Anwendungen werden im Anschluss diskutiert, mit dem Ziel einer Einschätzung der Nützlichkeit dieser Technik für den Zweck der Aufdeckung von algorithmischem Bias.
Persönliches Fazit
"Insgesamt bin ich rückblickend sehr zufrieden mit der Entscheidung, meine Bachelorarbeit am Lehrstuhl SSE geschrieben zu haben.
Ich bin mit der Betreuung meiner Bachelorarbeit durch meinen Supervisor vollends zufrieden. Er hat vorläufige Versionen der Bachelorarbeit aufmerksam gelesen und mir wertvolles und detailliertes Feedback gegeben. Positiv aufgefallen ist mir zudem, dass sowohl während der Präsentation des Proposals als auch während der Abschlusspräsentation eine große Anzahl von Mitarbeitern, in beiden Fällen auch Prof. Pohl, anwesend waren.
Das Thema meiner Bachelorarbeit habe ich als relativ anspruchsvoll empfunden, da es zum einen nicht auf Vorarbeiten des Lehrstuhls aufbaute und zum anderen ein Thema behandelte, für das ein gewisses Vorwissen notwendig war. Ich habe mir das Thema jedoch gezielt ausgesucht, da ich über ein derartiges Vorwissen verfügte und das Thema genau in den Bereich fiel, den ich mir für meine Bachelorarbeit gewünscht hatte.
Ich habe an mein Bachelorstudium kein Masterstudium angeschlossen, sondern die Universität nach Absolvieren des Studiums verlassen. An das konkrete Thema der Bachelorarbeit konnte ich in dem Unternehmen, in dem ich nun arbeite, zwar nicht anknüpfen, jedoch bin ich weiterhin im Bereich des maschinellen Lernens tätig und profitiere daher davon, dass die Bachelorarbeit auch praktische Anwendungen in diesem Bereich umfasste."
Jan Laufer, „Modellierung von Datenschutzgefährdungen im Fog-Computing anhand von Fallbeispielen aus dem EU-Forschungsprojekt FogProtect mithilfe der Modellierungssprachen UMLsec und SysML-Sec“, Bachelorarbeit, 2020
Abstract
Da die Anforderungen von modernen Anwendungen, wie eine geringe Latenzzeit zwischen End-geräten und verarbeitender Einheit zu erzielen, steigen, wird das Cloud-Computing durch Fog-Computing ergänzt. Fog-Computing stellt Rechenleistung an der Kante des Netzwerkes nahe den Endgeräten zur Verfügung und adressiert die genannten Anforderungen. Beim Einsatz von Fog-Computing müssen sowohl bereits bekannte Datenschutzgefährdungen aus den Bereichen IT-Sicherheit und Cloud-Computing als auch neu aufkommende Bedrohungen berücksichtigt werden. Datenschutz umfasst Datensicherheit und Privatsphäre im gesamten Datenlebenszyklus. Es ist insbesondere der Schutz personenbezogener Daten zu beachten. Aufgrund der Dynamik und der Charakteristika von Fog-Computing gibt es viele potenzielle Datenschutzrisiken, die berücksichtigt werden müssen.
Ziel dieser Arbeit ist die Modellierung von Datenschutzbedrohungen anhand von drei Fallstudien aus dem EU-Forschungsprojekt FogProtect, die jeweils unterschiedliche Szenarien des Fog-Computing beschreiben. Diese Szenarien sind Smart Manufacturing, Smart City und Smart Media. Um Datenschutzbedrohungen zu modellieren, werden die Modellierungssprachen UMLsec und SysML-Sec eingesetzt. Die Grundlage für die Modellierung ist das Deliverable 2.1 aus FogProtect sowie optionale Gespräche mit den FogProtect Partnern.
Die Modellierung hat ergeben, dass sowohl in UMLsec als auch in SysML-Sec der Großteil der potenziellen Datenschutzgefährdungen dargestellt werden kann, die in den Fallbeispielen aus Fog-Protect identifiziert wurden. Eine Bewertung durch die FogProtect Partner hat erwiesen, dass die Modellierungsergebnisse einen guten Überblick auf die Fallbeispiele und die enthaltenen potenziellen Datenschutzgefährdungen bieten. Außerdem sind die erstellten Diagramme von den FogProtect Partnern als nützlich für die weitere Entwicklung des Projekts eingestuft worden. Es ist jedoch anzumerken, dass die Diagrammtypen und ihre Nützlichkeit individuell unterschiedlich bewertet wurden.
Dass einige potenzielle Datenschutzgefährdungen nicht dargestellt werden können, hat zwei Gründe. Einerseits ist die Modellierung durch die Mächtigkeit der Modellierungssprachen einge-schränkt. Andererseits können aufgrund fehlender Details in der Modellierungsgrundlage Deliverable 2.1 die Modellierungssprachen nicht vollumfänglich eingesetzt werden. Die Untersuchung der Modellierungsergebnisse vor dem Hintergrund, ob Fog-Computing-Konzepte und Datenschutzsachverhalte mit UMLsec und SysML-Sec modelliert werden können, hat ergeben, dass beide Modellierungssprachen nur eingeschränkt dazu geeignet sind.
Persönliches Fazit
"Besonders hat mir am Prozess, die Bachelorarbeit am Lehrstuhl SSE zu schreiben, gefallen, dass Woche für Woche Teilziele erarbeitet werden konnten.
Zusätzlich hat man durch die Betreuung sowohl thematisch als auch hinsichtlich des wissenschaftlichen Schreibens viel dazu gelernt. Dies ermöglichte regelmäßig Feedback zu seinen neusten Ergebnissen in die weitere Arbeit mit aufzunehmen. Durch die begleitenden Bachelor-Vorträge konnte man über den Rand seiner eigenen Arbeit hinausschauen und die Themen anderer Studierenden verfolgen und lernen, worauf es beim Abschlussvortrag ankommt."

Theresa Wettig, „Erweiterung des Simulators MobFogSim zur Simulation von Location-Privacy-Angriffen auf Fog-Computing-Systeme“, Bachelorarbeit, 2020
Abstract

Privacy, vor allem Location-Privacy ist im Fog-Computing besonders gefährdet, da Daten in ihrer direkten Umgebung verarbeitet und zwischengespeichert werden. Da im Fog-Computing die Ressourcen von Geräten zwischen Cloud und Endgeräten genutzt werden, die oft nur schwach gesichert sind, können personenbezogene Informationen wie z. B. Identität und Standortdaten eines mobilen Endgerätes von einem Angreifer leicht in Erfahrung gebracht werden. Nun sollen mögliche Angriffe Location-Privacy mit dem Simulator MobFogSim simuliert werden. Dazu müssen das Datenmodell und die Funktionalität des Simulators um einige Komponenten (beispielsweise die Darstellung personenbezogener Daten, die Unterscheidung zwischen einem Angreifer und legitimen Benutzern sowie das in Erfahrung bringen von Informationen) erweitert werden. Die Implementierung der Simulator-Erweiterungen sowie der Simulation der Angriffe in einem Beispielszenario und die Diskussion der Ergebnisse, Beobachtungen und Erkenntnisse sind Inhalt dieser Ausarbeitung.
Persönliches Fazit
„Im Wintersemester 19/20 habe ich bei SSE meine Bachelorarbeit geschrieben. Besonders geholfen hat mir die sehr gute Betreuung, durch die die Arbeit viel Qualität gewinnen und sehr gut werden konnte. Auch in den Kolloquien gab es immer hilfreichen Input aus verschiedenen Perspektiven.
Dabei konnte ich auch einen Eindruck des Lehrstuhls erhalten und habe die Möglichkeit bekommen, im Anschluss an den Bachelorabschluss als wissenschaftliche Mitarbeiterin einzusteigen. Seitdem arbeite ich dort nun neben dem Masterstudium und konnte unter anderem ein Paper über die Ergebnisse der Bachelorarbeit einreichen, das momentan veröffentlicht wird.“
Tobias Braun "Untersuchung von Policy-based Reinforcement Learning bei dynamischen Änderungen des Zustandsraums am Beispiel eines adaptiven IoT-Systems“, Bachelorarbeit, 2020
Abstract

Reinforcement Learning umfasst denjenigen Bereich des Machine Learnings, welcher Techniken für das Lösen von sequenziellen Entscheidungsproblemen mittels evaluativem Feedback nutzt. Das Ziel der Arbeit ist die Realisierung und experimentelle Untersuchung von Policy-based Reinforcement Learning für ein konkretes Selbst-adaptives System („DingNet“). Insbesondere soll untersucht werden, inwiefern Policy-based Reinforcement Learning, als alternativer Ansatz zu tabularem Q-Learning, bei einer dynamischen Änderung der Anzahl der Zustände anwendbar ist. Die Ergebnisse des vorausgegangenen Bachelorprojekts zeigen, dass der der Lernprozess bei tabularem Q-Learning nur konvergiert, wenn der Zustandsraum, d.h. die Anzahl der Zustände, statisch bleibt. Das betrachtete Selbst-adaptive System ermöglicht jedoch Adaptionen, durch welche sich die Anzahl der Zustände verändert. Policy-based Reinforcement Learning ist eine Methode, welche mit einem Neuronalen Netz arbeitet. Prinzipiell ist Policy-based Reinforcement Learning damit in der Lage über bisher nicht gesehene Zustände hinweg zu generalisieren. Als konkreter Algorithmus soll proximal Policy optimization (PPO) verwendet werden. Die experimentellen Ergebnisse der Arbeiten zeigen, dass PPO bei statischem Zustandsraum durch die Generalisierung sample-effizienter, aber ungenauer lernt und PPO die Umgebung mit dynamischen Zustandsraum im Prinzip zwar lernen kann, dass jedoch eine Anpassung der Hyperparameter oder Erhöhung der Episodenzahl nötig ist.
Persönliches Fazit
"Die Abschlussarbeit war lehrreich und hat mir Spaß gemacht. Die Bearbeitung hat innerhalb eines vom Lehrstuhl SSE definierten Prozesses mit einem klaren Zeithorizont stattgefunden, sodass man gut planen konnte.
Durch das stets klare und ehrliche Feedback sowie die wöchentlichen Meetings habe ich bei der Bearbeitung zusätzliche Sicherheit gewonnen.
Der Umgang war dabei immer freundlich und locker. Besonders spannend fand ich die fachlichen Diskussionen, die bei der Bearbeitung entstanden sind. Ich habe nicht nur viel über meinen Themenbereich (Reinforcement Learning) gelernt, sondern konnte außerdem noch viel Erfahrung über wissenschaftliches Arbeiten im Allgemeinen sammeln."
Philipp Wallutis, “Experimentelle Untersuchung der varianzbasierten Verlässlichkeitsschätzung BAGV für Prozessprognosen", Bachelorarbeit, 2019
Abstract
Diese Arbeit befasst sich mit Geschäftsprozessprognosen (Predictive Process Monitoring) und der Schätzung der Verlässlichkeit einzelner Prozessprognosen. Im Besonderen werden numerische Prognosen von Ensembles künstlicher neuronaler Netze betrachtet und die Variance of a Bagged Model (BAGV) als Verlässlichkeitsschätzung untersucht. Der BAGV misst die Streuung der Einzelprognosen im Ensemble. Intuitive sollte eine Prognose, bei der die Einzelprognosen nah beieinander liegen, einen kleineren Fehler haben, als eine Prognose bei der die Einzelprognosen sehr weit streuen.
Die Arbeit untersucht experimentell, inwiefern eine Korrelation zwischen dem BAGV und dem Prognosefehler besteht, um die Güte des BAGV als Schätzer für die Prognosegenauigkeit zu bewerten. Als Datengrundlage werden vier Datensätze (CARGO2000, BPIC2012, BPIC2017 und TRAFFICFINE) verwendet. Aufgrund der Umfänge der Datensätze wurde das Experiment automatisiert. Die hierzu programmierte Experimentierumgebung liest automatisiert bis zu 100 Einzelprognosen zu einer Prozessinstanz aus und ermittelt den BAGV und den Prognosefehler. Für alle vier Datensätze konnte eine klare Korrelation zwischen BAGV und Prognosefehler nachgewiesen werden, welcher somit einen Indikator für die Nutzbarkeit des BAGV als Verlässlichkeitsschätzung liefert. Im Vergleich mit den Ergebnissen zu vorangegangen Arbeiten bietet der BAGV eine konstant gute Korrelation in allen Datensätzen.
Persönliches Fazit
"Die Abschlussarbeit am Lehrstuhl SSE ermöglichte mir einen Einblick in das spannende Feld der künstlichen neuronalen Netze und dem Machine Learning.
Durch die enge und kompetente Betreuung wurde ich dem Ziel eine wissenschaftliche Arbeit zu erstellen konsequent nähergebracht. Die offene Fehlerkultur und das schnelle und direkte Feedback halfen mir meine Arbeitsweise auf ein neues Niveau zu steigern.
Wer sich für diesen Wissenschaftsbereich begeistern kann, dem kann ich den Lehrstuhl SSE uneingeschränkt weiterempfehlen!"

Norman Reddig, „Experimenteller Vergleich zwischen median- und mittelwert-basierten Ensembleprognosen für Geschäftsprozesse“, Bachelorarbeit, 2019
Abstract

Diese Arbeit befasst sich mit dem experimentellen Vergleich von mittelwert- und median-basierten Ensembleprognosen für das Predictive Process Monitoring. Im Besonderen untersucht diese Arbeit experimentell, inwiefern die Genauigkeit von Ensembleprognosen durch ein mittelwert- und median-basiertes Aggregationsverfahren beeinflusst wird. Prinzipiell ist median-basierte Aggregation robuster gegenüber Ausreißern. Als Basis für das Experiment werden binäre und nummerische Prognosen von Ensembles rekurrenter neuronaler Netze für vier Datensätze aus dem Predictive Process Monitoring genutzt. Zur Messung der Prognosegenauigkeit werden sowohl binäre Genauigkeitsmetriken, wie z.B. Precision und Recall, als auch die nummerische Genauigkeitsmetrik, Relative Mean Absolut Error, verwendet. Auf-grund der Größe der Datensätze wurde die Experimentdurchführung automatisiert. Für alle vier Datensätze konnten nur sehr geringe Unterschiede zwischen mittelwert- und median-basierten Ensembleprognosen beobachtet werden. Eine weitergehende Analyse der Datensätze zeigte, dass diese sehr geringen Unterschiede durch den relativ geringen Anteil an Ausreißern in den Prognosen begründet sind.
Persönliches Fazit
"Ich würde am Lehrstuhl SSE immer wieder eine wissenschaftliche Arbeit schreiben wollen.
Besonders bei der Betreuung wurde sich jede Woche die Zeit genommen in einem persönlichen Gespräch offene Fragen und Kritikpunkte an meiner Bachelorarbeit auszudiskutieren, wodurch auch die Motivation gestiegen ist jede Woche etwas zu schreiben. Zusätzlich wusste ich durch die Betreuung, wo ich stehe und wurde am Ende beim Abschlussvortrag bzw. der Abgabe nicht Böse überrascht.
Mir wurde ein Thema für die Bachelorarbeit vorgeschlagen mit dem ich erste Berührungspunkte mit Machine Learning sammeln konnte, was mir im vorherigen Bachelorstudium gefehlt hat.
Die Erfahrungen mit Machine Learning und wissenschaftlichen Arbeiten helfen mir noch immer in meinem anschließenden Masterstudium."
Michael Schröder, „Evaluierung eines Algorithmus für die Ressourcenzuteilung in einer Cloud mit realen Nutzungsdaten“, Bachelorarbeit, 2017
Abstract
Die Ressourcenzuteilung für virtuelle Maschinen ist ein wichtiges Optimierungsproblem mit großem Einfluss auf den Energiebedarf und die Leistungsfähigkeit von Rechenzentren. Das Problem besteht darin, die virtuellen Maschinen (VM) möglichst ideal auf die physischen Maschinen (PM) zu verteilen, um die physischen Ressourcen optimal auszunutzen. Das wird erreicht, indem die VM so auf den PM zusammengefasst bzw. umverteilt werden, dass ungenutzte PM in einen energiesparenden Zustand wechseln. Dadurch sinkt der Energiebedarf des Rechenzentrums. In dieser Arbeit wird die Implementierung des Branch-and-bound-Algorithmus (bnb) von Bartók und Mann evaluiert, die ursprünglich von Dávid Bartók entwickelte Implemen-tation des Algorithmus vmbb erweitert und das Verhalten des Algorithmus bei der Verarbeitung von realen Nutzungsdaten analysiert. Im Besonderen wurde der Einfluss der verschiedenen Parameter des Algorithmus untersucht. Zur Durchführung der Simulation wurde die Software zunächst ausführlich dokumentiert und anschließend erweitert. Unter anderem wurde eine Datenbankanbindung ergänzt, um die Ein- und Ausgaben zu speichern. Auf diese Weise wurde eine bessere Analyse der Daten ermöglicht. Es wurden reale Nutzungsdaten mit den Informationen über CPU- und Arbeitsspeicher-Auslastung genutzt, um einen mehrtägigen Betrieb zu simulieren. Die Ergebnisse der Simulationen verschiedenen Algorithmus-Konfigurationen wurden in zwei Szenarien mit denen von Gurobi verglichen. Durch den Einsatz von bnb konnten in einem realitätsnahen Szenario über 35% der Kosten im Vergleich zum Betrieb aller PM eingespart werden.
Persönliches Fazit
"Mir gefiel die gute Kommunikation und strukturierte Betreuung. Das Thema und der Rahmen des Projektes waren klar abgestimmt. Wirklich gut fand ich den regelmäßigen Austausch über die aktuellen Ergebnisse und Ideen.
Die Forschungsarbeit und die Gewinnung von Erkenntnissen waren eine tolle Erfahrung."
